
먼저 이전에 예시 프로젝트를 생성하여 가상의 음원플랫폼으로 Spotify Developer 사이트에서 앨범, 트랙, 아티스트 API 요청으로 데이터를 가져와 DB에 넣었다.


쿼리셋(QuerySet)
먼저 쿼리셋은 무엇일까?
쿼리셋은 일반적으로 데이터베이스를 조회하기 위한 기능을 제공하는 개념을 의미한다. ORM을 통해 DB와 상호작용하는 인터페이스를 제공한다. ORM에 대한 개념은 이전에 작성했던 글을 참조하면 된다.
아래 그림을 보면 데이터를 조회하기 위해 필터링하는 구간까지가 쿼리셋을 의미하고 [0] 인덱싱으로 인스턴스를 얻을 수 있다.

READ
먼저, 기본적으로 쿼리셋을 통해 데이터를 가져오는 실습을 진행해보자.
데이터를 가져올 때는 `all(), get(), filter(), exclude(), exist()`등 함수를 사용해서 데이터를 조회할 수 있는데 exclude()은 제외의 의미이며 해당 파라미터에 속하지 않은 데이터 목록을 가져온다.
또한 filter(), get() 차이에서 중요한 점이 있는데 해당 데이터가 존재하지 않으면 get은 오류를 발생시키지만 filter는 None 값을 반환하게된다.

Read+
- count() : 데이터의 개수를 조회
- first(), last() : 첫번째 혹은 마지막 데이터 조회, 없으면 None을 반환한다.
- order_by() : 특정 필드대로 정렬, 필드 내에 `-` 부호를 붙이면 내림차 순으로 정렬하고 `?`를 입력하면 랜덤 순서로 정렬한다.
- earliest() / latest() : 가장 이른/ 최근 데이터를 반환한다.
- get() : 1개의 데이터를 조회
- exist() : 쿼리셋에 데이터가 존재하는지 True/False로 반환한다.
- exclude : 제외 (where not)
조건
조건을 넣을 때 `__`(Look up)을 넣어 조건을 판단한다.
- exact : 일치하는 조건 (=)
- iexact : 대소문자 가리지 않고 일치하는 조건 (=)
- contains : 부분 일치 조건 (like "%~%)
- in : 여러 조건이 포함되는 경우 (필드 in ())
- gt, lt, gte, lte : > < >= <=
- startswith, endswith : ~로 시작하는, ~로 끝나는 %~ ~%
- range : 범위 (between and)
- date, year, month, day, week, weekday : 날짜 조건(date_format(date, "%Y")
- regex : 정규 표현식

정렬 조건
- order by(): 역순인 경우 -를 붙입니다.
- reverse() : 데이터를 역순으로 가져와서 반환할 때
- union() : 하나의 쿼리셋으로 합칠 때
- intersection() : 교집합
- difference() : 중복되지 않은 값을 가져온다.
ForeignKey Filter & Reverse Accssors
# kang으로 시작하는 집주인의 집들 쿼리셋 반환
# ForeignKey -> owner 필드
Room.objects.filter(owner__username__startswith="kang")
# Reverse Accessors
# room 필드가 없는 user(owner)의 모든 집 쿼리셋 반환
user.room_set.all()
# related_name
# room 모델에 owner 필드에 related_name="rooms" 을 추가하면 아래 처럼 작성 가능
user.rooms.all()쿼리셋 체이닝 + Lazy Loding
단일 메서드를 사용해도 되지만 여러개의 메서드를 엮어 체이닝하여 복잡한 쿼리를 만들 수 있다.
이 체이닝이 가능한 이유는 쿼리셋의 Lazy Loding이라는 강력한 기능 때문인데 쿼리셋을 정의만 했다가 구체적으로 데이터가 필요한 요청을 받았을 때 그때서야 로딩한다는 개념이다.
다음 코드를 보면 21번 쿼리셋을 정의한 시점에는 아직 DB에 쿼리가 실행되지 않은 상황이다. 그리고 23번 반복문을 통해 출력을 한 상태가 되서야 21번 데이터가 로딩되어 실제로 데이터베이스에 데이터를 가져오게 된다. 참고공식문서

위에 경우를 아래 처럼 쿼리 했을 때 SQL 쿼리를 확인해보면 출력한 시점부터 쿼리가 실행되는 것을 확인할 수 있다.

그렇다면, Lazy Loding의 이점은 뭘까?
우선, 데이터를 정의하고 출력하기전 시점까지는 데이터를 실제로 조작하지 않기 때문에 효율적으로 자원을 사용할 수 있게 된다. 즉, DB 성능에 영향을 미치지 않게 된다. 쿼리가 실행되기 전까지 실제로 DB에 접근하지 않는다는 말이 지연 평가라는 얘기이다.
💡 Q 클래스
복잡한 쿼리를 구성하는 방법으로 Q 클래스를 사용하는 방법도 있다.
조건을 복잡하게 쿼리할 수 있는 방법으로 집합 연산자를 사용해 결합할 수 있다.

CRUD
- `클래스.objects.create()` : 데이터를 생성
- `오브젝트.objects.update()` : 데이터를 수정 + `오브젝트.save()`
- `오브젝트.objects.delete()` : 데이터를 삭제

Aggregate, Annotate, Values
위 세가지 메서드는 데이터를 검색하거나 집계할 때 사용하는 메서드들이다.
`django.db.models`에서 Count(), Min(), Max(), Sum(), Avg()등 연산자를 불러와 사용할 수 있다.
- Aggregate : 쿼리의 결과를 새로운 한개 필드로 생성하는 메서드로 데이터를 집계하는 데 사용한다.
- Annotate : 특정 필드의 추가정보를 제공할 때 사용한다.
- values : SQL의 GROUP BY와 같은 방법으로 특정 필드를 생성하거나 고유 값을 리스트로 생성할 때 사용한다.

우리는 어떻게 SQL 쿼리를 볼 수 있을까?
실제로 Django ORM을 통해 입력하는 쿼리와 직접 SQL로 쿼리하는 것과 다를 때가 있다.
그래서 우리는 성능 향상을 위해 Django ORM 쿼리를 최적화 할 줄 알아야 한다.
그럼 어떻게 SQL 쿼리를 확인할 수 있을까?
먼저 이전에 쿼리셋 체이닝을 통해 사용해보았던 디버깅 방식이다. 해당 쿼리셋에 `.query` 메서드를 붙여 출력하면 SQL 쿼리문을 확인할 수 있듯 `explain` 메서드를 통해 쿼리 실행을 계획을 출력할 수 있다.

즉, 실행 계획의 두번째 레코드로 최 상위 레벨에 위치한 스캔 작업을 나타낸다.
또 다른 방법은 Logging의 결과를 확인하는 방법이다.
아래 코드를 `settings.py`에 적어두면 동작을 수행할 때 로그를 남긴다. 이는 어떤 동작을 하는지 디버깅할 때 유용하다.
그런데, 로그 남길 내용이 생각보다 많아서 용량도 고려해봐야할 것 같다.
LOGGING = {
'version': 1, # 로깅 버전
'disable_existing_loggers': False,
'handlers': {
'console': {
'class': 'logging.StreamHandler',
},
},
'loggers': { # 로거를 수행하는 주체
'django.db.backends': { # Django DB 벡엔드를 다룸
'handlers': ['console'],
'level': 'DEBUG',
},
},
}
마지막으로 UI 툴을 활용하는 방법이다.
`django-debug-toolbar` 나 `django-silk`를 사용하면 해당 쿼리가 어떻게 SQL로 어떻게 실행되는지 알 수 있다.
이 두가지 도구는 디버깅과 성능을 분석해주는 도구인데 이건 멘토님이 Django-silk를 추천한다고 한다. 물론 서로 목적이나 상황에 따라 더 우수한 면이 있지만 결론적으로 프로덕션 환경에서 Silk를 사용할 수 있다는 것이다. django-debug-toolbar는 로컬에서 밖에 사용 못한다고 한다. 이 포스팅에서는 Django-silk를 설치하는 방법을 다루도록 한다. 그리고 해당 링크를 참조하면 `django-debug-toolbar`를 설치하는 방법을 확인할 수 있다.
처음은 일단 silk를 설치하고 앱과 미들웨어에 Silk 설정을 넣어준다.
pip install django-silkINSTALLED_APPS = [
...
'silk',
]
MIDDLEWARE = [
...
'silk.middleware.SilkyMiddleware',
]
그다음, urlpattern에 silk를 추가한다.
urlpatterns = [
path('admin/', admin.site.urls),
path('silk/', include('silk.urls')),
...
]
UI는 정상적으로 잘 작동하는 것 같다.
아직 API 요청은 하지 않은 임시 프로젝트라 별 내용은 없는데 쿼리문의 상세 내용과 걸린 시간도 확인이 가능한 것 같다.
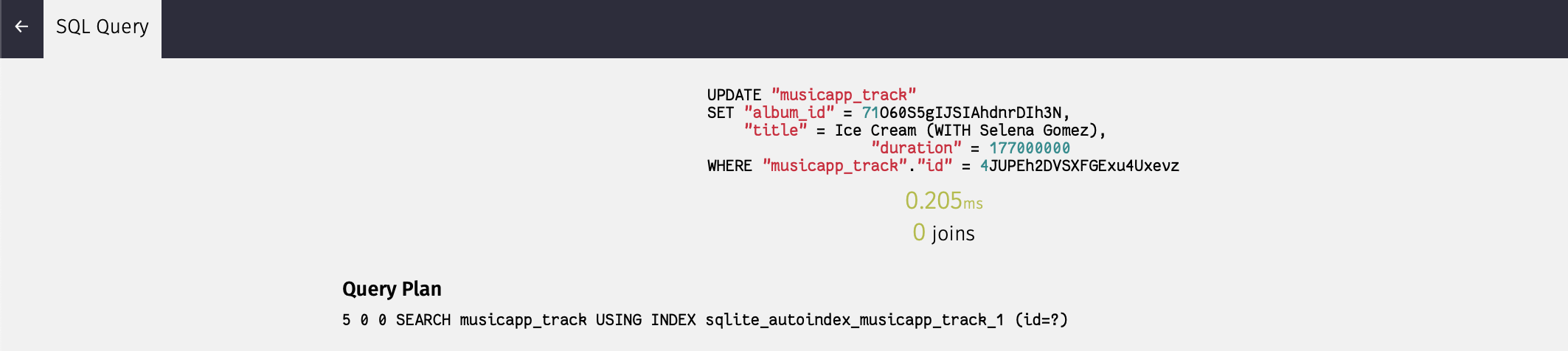
본격적인 쿼리 최적화에 대해 다음 포스팅에 이어갈 예정이다.
도움이 되는 참고자료
https://www.qu3vipon.com/django-orm
SQL을 이해하고 사용하는 Django ORM
목차
www.qu3vipon.com
https://woolbro.tistory.com/69
[tip] Django 디버깅하기 - django-debug-toolbar
안녕하세요, 장고로 개발을 하는 여러분들에게 희소식이 있습니다! 개발자들에게는 debug가 필수적인데요, django와 같은 프레임워크는 어떻게 debug할까요?? 한번 살펴보도록 하겠습니다. 기본적으
woolbro.tistory.com
'Web > Django' 카테고리의 다른 글
| Django Rest Framework - (1 : API 테스트 해보기) (0) | 2023.12.25 |
|---|---|
| [Django] DB 쿼리 최적화를 다양한 방법들을 정리해보았다. (0) | 2023.12.20 |
| Django - 객체 참조 관계 (0) | 2023.11.29 |
| [Django] CRUD 구현 (0) | 2023.11.29 |
| User Model 커스텀 하기 (0) | 2023.11.28 |



