
운영체제를 공부하면서 느꼈던 토픽에 대해 공유해보려고 한다. 멀티 스레딩은 복수의 스레드가 자원을 공유해 프로세스를 실행시키기 때문에 좀 더 빠른 속도로 프로세스를 실행할 수 있다고 한다. 그런데 파이썬에는 멀티 스레드를 사용한다 하더라도 싱글 스레드와 별반 차이가 없다고 한다. 이유는 GIL 정책 때문이라고 하는데... 🧐 이유에 대해 궁금해지기 시작했다.
Multi Thread?
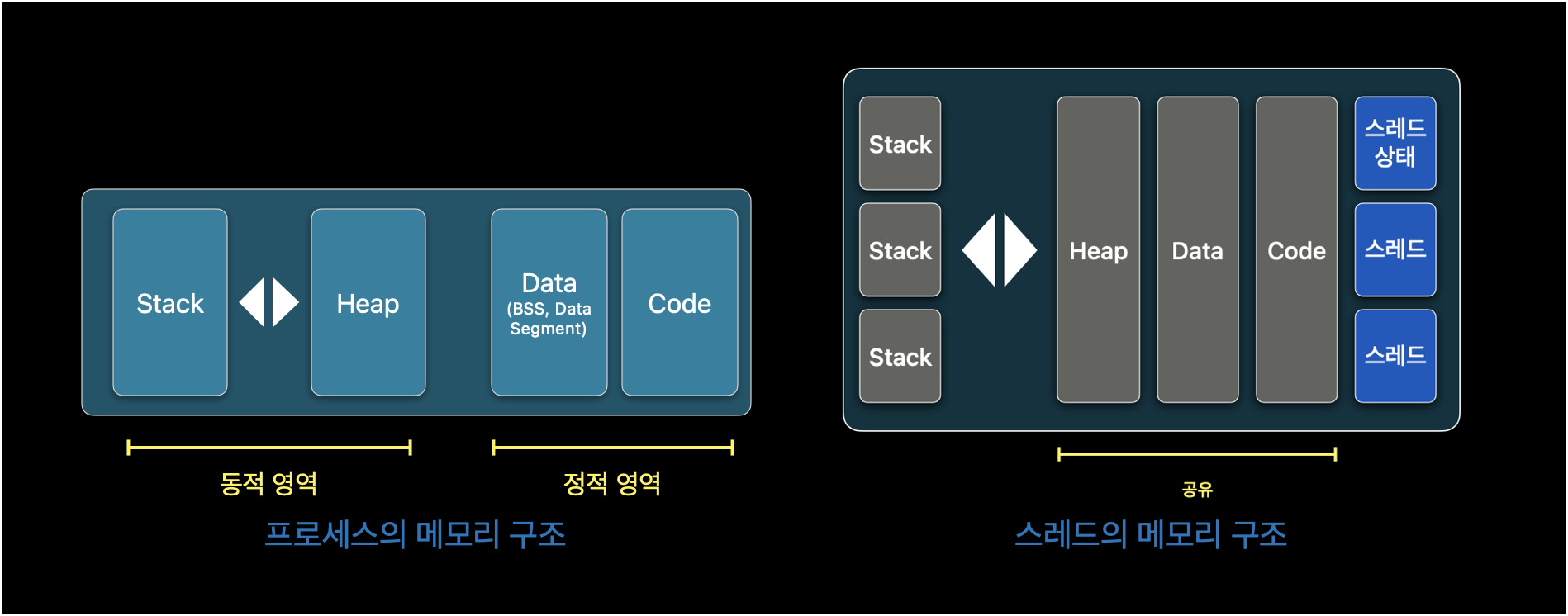
우선, 스레드(Thread)는 프로세스에 실행되는 하나의 작업 단위를 말한다. 스레드의 메모리 구조를 보면 프로세스와 다르게 대부분의 영역이 공유 영역으로 되어 있다. 즉, 멀티 스레드를 사용하면 스레드 끼리 해당 영역을 공유하고 있기 때문에 메모리를 효율적으로 사용할 수 있게된다. 추가로 멀티 프로세싱(Processing)이라는 게 있는데 다수의 프로세서가 다수의 프로세스를 처리하는 것을 말한다. 여기서 중요한 것은 프로세서가 프로세스(Process)를 의미하는게 아니라 프로세서(CPU)를 의미하는 것이다. 만약, 두개 이상의 스레드나 프로세스가 동시에 접근하게되면 어떻게 될까? 이렇게 동시에 접근하는 상황을 경쟁 상태(race condition)라고 하는데 프로세스 동기화(Process Synchronization)을 통해 이 문제를 해결할 수 있다. 프로세스 동기화의 예시로 뮤텍스, 세마포어 등이 있다.
파이썬에서 멀티 스레딩을 구현해보자.
파이썬에서 멀티 스레드을 구현하면 싱글 스레드와 별 반 차이가 없다는 것을 알아 볼 차례이다. 파이썬에는 `threading` 모듈을 이용해 스레드를 구현할 수 있다. 아래 코드에서는 0부터 100,000,000까지의 합을 구하는 프로그램을 만들어보았다.
from threading import Thread # 이전 thread 모듈은 더이상 사용하지 않는다.(deprecated)
import time
def working(start, end):
result = 0
for i in range(start, end):
result += i
return
if __name__ == "__main__":
START, END = 0, 100_000_000
th1 = Thread(target=working, args=(START, END))
start_time = time.time()
th1.start() # 스레드 시작
th1.join() # 스레드가 종료될 때 까지 기다림
end_time = time.time()
print(f"⏰ Result : {end_time - start_time:.3f}초")
`th1`이라는 싱글 스레드를 이용해 실행 시간을 확인해본 결과 약 4.9초가 걸렸다. 다음은 `t2` 스레드를 추가해서 멀티 스레드로 구현을 해보기로 했다. 데이터를 반으로 나누어 각 스레드에게 처리하는 코드를 만들어보았다.
if __name__ == "__main__":
START, END = 0, 100_000_000
th1 = Thread(target=working, args=(START, END//2))
th2 = Thread(target=working, args=(END//2, END))
start_time = time.time()
th1.start()
th2.start()
th1.join()
th2.join()
end_time = time.time()
print(f"⏰ Result : {end_time - start_time:.3f}초")
결과적으로 약 4.8초가 나왔다. 멀티 스레드로 구현했음에도 불구하고 성능이 향상되지 않았다.
이 이유는 파이썬 GIL 정책 때문이다.
GIL 정책
GIL(Global Interpreter Lock) 정책은 파이썬의 인터프리터가 하나의 스레드만 하나의 바이트 코드를 실행시키도록 Lock을 거는 정책이다. 이로 인해 멀티 스레딩을 사용하더라도 싱글 스레드의 속도와 별 반 차이가 없게 되는 것이다. 일단 대충은 알겠으나 정확하게 감이 잡히지는 않는다. Python wiki에서는 GIL을 다음과 같이 정의하고 있다.
In CPython, the global interpreter lock, or GIL, is a mutex that protects access to Python objects, preventing multiple threads from executing Python bytecodes at once. The GIL prevents race conditions and ensures thread safety. A nice explanation of how the Python GIL helps in these areas can be found here. In short, this mutex is necessary mainly because CPython's memory management is not thread-safe.
Python 코드를 실행할 때 멀티 스레드를 사용하는 경우 파이썬 객체에 접근할 수 있도록 제한하는 Mutex이다. 자세한 설명은 해당 링크를 참고하면 되고 짧게 말해서, 이 뮤텍스(Mutex)가 필요한 이유는 CPython의 메모리 관리가 Thread-safe하지 않기 때문이란다.
결국엔 GIL은 Mutex라고 한다. 그리고 CPython의 메모리 관리가 Thread-safe하지 않다는 이유 때문에 필요하다고 한다. 운영체제에서 프로세스 동기화를 공부해봤다면 Mutex를 들어봤을 것이다. Mutex(뮤텍스)는 실행시간이 겹치지 않게 단독으로 실행하게 하는 기술을 말한다. 뮤텍스 알고리즘으로 데커 알고리즘, 피터슨 알고리즘, 제과점 알고리즘이 있는데 이렇게 자세히는 다루지 않을 것이다. 뮤텍스의 역할은 하나의 스레드가 실행되면 다른 스레드는 기다려야한다.

그럼 Cpython의 메모리 관리가 Thread-safe하지 않다는 말은 무엇일까?
파이썬 일반적으로 C로 구현된 인터프리터 언어이다. 그렇다고 우리가 파이썬 코드를 작성하면 C로 바꾸는 게 아니라 컴파일하여 Bytecode로 바꾸고 그 다음에야 인터프리터가 가상머신을 통해 한 줄씩 실행하는 식이다. 우리가 파이썬 내부 파일을 보면 `.pyc`라는 파일을 볼 수 있는데 이것이 Cpython이 컴파일한 bytecode가 들어 있는 것이다.
파이썬은 스크립트 언어(Scripting)이자 인터프리터(Interpreter) 언어이자 컴파일러 언어이다.
인터 프리터는 원시코드 명령어를 한번에 한줄씩 실행하는 프로그램을 말하며 소스코드를 바로 실행하는 언어이다.

그리고 찾아본 결과 Thread-safe 한다는 의미는 경쟁 상태가 생기지 않는다는 의미이다. 그렇다면 경쟁 상태가 생기기 때문에 Mutex가 필요하다고 해석해볼 수 있다. 그렇다면 Cpython은 메모리 관리를 어떻게 하는 걸까? 이건 해당 포스팅을 참고하면 답이 될 듯하다.
결국엔 GIL은 Reference Counting으로 메모리하는 과정에서 경쟁 상태가 일어나면 메모리에 대한 유실이 생기기 때문에 이를 해결하기 위해 GIL이 필요하다고 한다. 그리고 이 잠금 기능을 하나하나의 객체마다 적용하면 성능적으로 낭패를 보니까 완전히 하나의 스레드만 사용할 수 있게 전역으로 인터프리터를 잠가버리는 식으로 문제를 해결하기로 한 것이다.
Python은 왜 GIL을 제거하지 않는지
요즘같은 시대에 싱글 코어만 쓰는 게 아니라 더블 코어, 헥사 코어로 올라가는 추세이다. 그런데 왜 GIL을 사용하는 것이고 왜 제거하지 않는 것일까? 역사적으로, Python은 운영체제에 스레드라는 개념이 없었을 때 부터 만들고 있었고 GIL이 C extenstion에 의존하고 있었으므로 제거로 성능을 개선시킬 수 없었다. 하지만, 그렇다고 무의미한 파이썬 멀티 스레드인 것은 아니다. GIL은 CPU 동작에서 적용되는 것이기 때문에 CPU 동작을 마치고 I/O 작업을 실행하게되면 다른 스레드는 CPU 동작을 실행할 수 있다. 즉, I/O 작업이 많은 프로그램에서는 멀티 스레드가 좋은 성능을 낼 수 있는 것이다. 참고자료↗
GIL의 불편함을 해결하기 위해
사실 멀티 스레딩을 대신할 수 있는 방법은 여러가지 존재한다.
- 병렬 처리는 thread 말고도 멀티 프로세싱이나 asyncio, celery를 사용하는 방법을 택하면 된다.
- 동시 처리가 필요하다면 다른 파이썬 구현체를 생각해보면 된다. Jython, Pypy 등 다양하게 존재한다.
동시성과 병렬성의 차이
동시성(Concurrency)
병렬성과 비슷한 효과를 갖기 위해 번갈아 가면서 작업을 수행하는 방식이다. 실제로 동시에 처리하는 방식이 아니라 동시에 처리하게끔 보이기 위한 방식이다.
병렬성(Parallelism)
실제로 동시에 이루어지는 작업이다.
멀티 프로세싱(Multi Processing)
`threading`을 `multiprocessing`으로 변경해서 합을 계산해보았다.
결과는 약 2.4초 정도로 지금까지 가장 빠른 속도가 나왔다. 이전 멀티 스레딩에 비해 성능이 꽤 향상되었다는 것을 확인할 수 있다. 하지만 멀티 프로세싱은 멀티 스레드보다 무겁기 때문에 병목 현상이 일어날 수 있다는 점에 명심해야 한다. 멀티 스레드보다 무거운 이유는 프로세스는 각자 고유 메모리 영역을 가지고 있기 때문이다. 그래도 각 프로세스는 병렬로 CPU 작업이 가능하기 때문에 분산처리를 구현할 수 있다는 장점이 있다.
from multiprocessing import Process
import time
def working(start, end):
result = 0
for i in range(start, end):
result += i
return
if __name__ == "__main__":
START, END = 0, 100_000_000
pr1 = Process(target=working, args=(START, END//2))
pr2 = Process(target=working, args=(END//2, END))
start_time = time.time()
pr1.start()
pr2.start()
pr1.join()
pr2.join()
end_time = time.time()
print(f"⏰ Result : {end_time - start_time:.3f}초")
Asyncio
Asyncio는 동시성 프로그래밍 설계를 위해 코루틴을 실행하고 관리하는 파이썬 패키지이다. Python 3.7부터 생겼다.
☕️ 포스팅이 도움이 되었던 자료
- 멀티 프로세싱과 멀티 스레딩의 차이점 - Murphy
- 파이썬 멀티 쓰레드와 멀티 프로세스 - Nathan Kwon
- Python은 어떻게 동작하는가? - cjh5414.github.io
- 왜 Python에는 GIL이 있는가? - 개발새발로그
- What is the Python Global Interpreter Lock? - MyRealPython
- https://www.youtube.com/watch?v=Obt-vMVdM8s&feature=youtu.be&themeRefresh=1
- 파이썬 New GIL을 이해하기 - 또리 장군
오늘도 저의 포스트를 읽어주셔서 감사합니다.
설명이 부족하거나 이해하기 어렵거나 잘못된 부분이 있으면 부담없이 댓글로 남겨주시면 감사하겠습니다.
'Programming > Python' 카테고리의 다른 글
| 깊은 복사와 얕은 복사 (0) | 2024.04.08 |
|---|---|
| Garbage Collector 동작 방식 (0) | 2024.02.07 |
| 파이썬 패키지와 모듈 (0) | 2024.01.02 |
| 이터레이터? 제너레이터? (0) | 2023.11.28 |
| 파이썬 함수 Deep-Dive (0) | 2023.11.22 |



